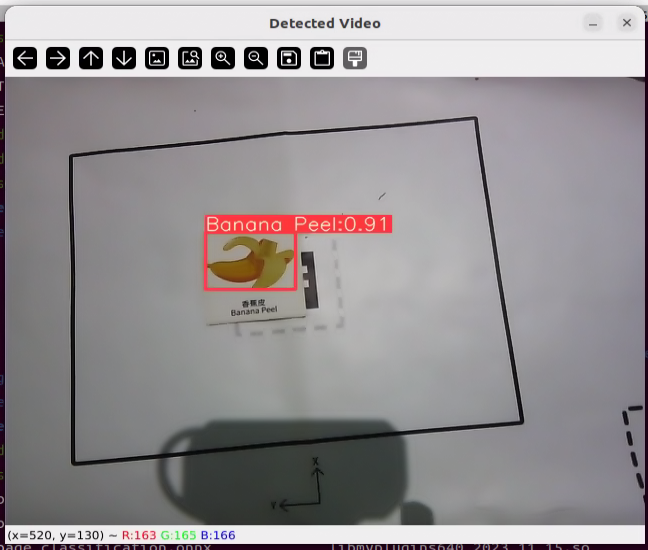
5. ROS1-ROS+Deep Learning Basic Lesson
5.1 Machine Learning Introduction
5.1.1 What “Machine Learning” is
Machine learning forms the foundation of artificial intelligence and is essential in imbuing machines with intelligent capabilities. It is an interdisciplinary field that draws upon probability theory, statistics, approximation theory, convex analysis, algorithm complexity theory, and other related disciplines.
In essence, machine learning is concerned with the study of how computers can acquire new knowledge or skills by simulating or implementing human learning behaviors. It involves the reorganization of existing knowledge structures to continuously improve machine performance. From a practical perspective, machine learning involves training models using data and using those models to make predictions.
For example, AlphaGo was the first artificial intelligence robot to defeat a human professional Go player and become the world champion. The main working principle behind AlphaGo was deep learning, which involves learning the internal laws and representation levels of sample data to extract valuable information.
5.1.2 Types of Machine Learning
Machine learning can be broadly categorized into two types: supervised learning and unsupervised learning. The key distinction between these two types lies in whether the machine learning algorithm has prior knowledge of the classification and structure of the dataset.
Supervised Learning
Supervised learning involves providing a labeled dataset to the algorithm, where the correct answers are known. The machine learning algorithm uses this dataset to learn how to compute the correct answers. It is the most commonly used type of machine learning.
For instance, in image recognition, a large dataset of dog pictures can be provided, with each picture labeled as “dog”. This labeled dataset serves as the “correct answer”. By learning from this dataset, the machine can develop the ability to recognize dogs in new images.
Unsupervised Learning
Unsupervised learning involves providing an unlabeled dataset to the algorithm, where the correct answers are unknown. In this type of machine learning, the machine must mine potential structural relationships within the dataset.
For instance, in image classification, a large dataset of cat and dog pictures can be provided without any labels. Through unsupervised learning, the machine can learn to divide the pictures into two categories: cat pictures and dog pictures.
5.2 Framework Introduction
There are a large variety of machine learning frameworks. Among them, PyTorch, Tensorflow, MXNet and paddlepaddle are common.
5.2.1 Pytorch
PyTorch is a powerful open-source machine learning framework, originally based on the BSD License Torch framework. It supports advanced multidimensional array operations and is widely used in the field of machine learning. PyTorch, built on top of Torch, offers even greater flexibility and functionality. One of its most distinguishing features is its support for dynamic computational graphs and its Python interface.
In contrast to TensorFlow’s static computation graph, PyTorch’s computation graph is dynamic. This allows for real-time modifications to the graph as computational needs change. Additionally, PyTorch enables developers to accelerate tensor calculations using GPUs, create dynamic computational graphs, and automatically calculate gradients. This makes PyTorch an ideal choice for machine learning tasks that require flexibility, speed, and powerful computing capabilities.
5.2.2 TensorFlow
TensorFlow is a powerful open-source machine learning framework that allows users to quickly construct neural networks and train, evaluate, and save them. It provides an easy and efficient way to implement machine learning and deep learning concepts. TensorFlow combines computational algebra with optimization techniques to make the calculation of many mathematical expressions easier.
One of TensorFlow’s key strengths is its ability to run on machines of varying sizes and types, including supercomputers, embedded systems, and everything in between. TensorFlow can also utilize both CPU and GPU computing resources, making it an extremely versatile platform. When it comes to industrial deployment, TensorFlow is often the most suitable machine learning framework due to its robustness and reliability. In other words, TensorFlow is an excellent choice for deploying machine learning applications in a production environment.
5.2.3 PaddlePaddle
PaddlePaddle is a cutting-edge deep learning framework developed by Baidu, which integrates years of research and practical experience in deep learning. PaddlePaddle offers a comprehensive set of features, including training and inference frameworks, model libraries, end-to-end development kits, and a variety of useful tool components. It is the first open-source, industry-level deep learning platform to be developed in China, offering rich and powerful features to developers worldwide.
Deep learning has proven to be a powerful tool in many machine learning applications in recent years. From image recognition and speech recognition to natural language processing, robotics, online advertising, automatic medical diagnosis, and finance, deep learning has revolutionized the way we approach these fields. With PaddlePaddle, developers can harness the power of deep learning to create innovative and cutting-edge applications that meet the needs of users and businesses alike.
5.2.4 MXNet
MXNet is a top-tier deep learning framework that supports multiple programming languages, including Python, C++, Scala, R, and more. It features a dataflow graph similar to other leading frameworks like TensorFlow and Theano, as well as advanced features such as robust multi-GPU support and high-level model building blocks comparable to Lasagne and Blocks. MXNet can run on virtually any hardware, including mobile phones, making it a versatile choice for developers.
MXNet is specifically designed for efficiency and flexibility, with accelerated libraries that enable developers to leverage the full power of GPUs and cloud computing. It also supports distributed computing across dynamic cloud architectures via distributed parameter servers, achieving near-linear scaling with multiple GPUs/CPUs. Whether you’re working on a small-scale project or a large-scale deep learning application, MXNet provides the tools and support you need to succeed.
5.3 GPU Acceleration
5.3.1 GPU Accelerated Computing
A graphics processing unit (GPU) is a specialized micro processor used to process image in personal computers, workstations, game consoles and mobile devices (phone and tablet). Similar to CPU, but CPU is designed to implement complex mathematical and geometric calculations which are essential for graphics rendering.
GPU-accelerated computing is the employment of a graphics processing unit (GPU) along with a computer processing unit (CPU) in order to accelerate science, analytics, engineering, consumer and cooperation applications. Moreover, GPU can facilitate the applications on various platforms, including vehicles, phones, tablets, drones and robots.
5.3.2 Comparison between GPU and CPU
The main difference between CPU and GPU is how they handle the tasks. CPU consists of several cores optimized for sequential processing. While GPU owns a large parallel computing architecture composed of thousands of smaller and more effective cores tailored for multitasking simultaneously.
GPU stands out for thousands of cores and large amount of high-speed memory, and is initially intended for processing game and computer image. It is adept at parallel computing which is ideal for image processing, because the pixels are relatively independent. And the GPU provides a large number of cores to perform parallel processing on multiple pixels at the same time, but it only improves throughput without alleviating the delay. For example, when receives one message, it will use only one core to tackle this message although it has thousands of cores. GPU cores are usually employed to complete operations related to image processing, which is not universal as CPU.
5.3.3 Advantage of GPU
GPUs, equipped with multiple cores, are well-suited for large-scale parallel data processing, providing distinct advantages in efficiently handling extensive repetitive tasks, particularly in multimedia processing.
Consider deep learning, where the neural network designs aim to analyze massive amounts of data swiftly. This aligns with the strength of GPUs in processing vast datasets.
Additionally, GPU architecture, optimized based on CPU architecture, lacks specialized image processing algorithms. Consequently, beyond the realm of image processing, GPUs find widespread applications in scientific computing, cryptography, numerical analysis, big data processing, financial analysis, and other domains that demand parallel computation.
5.4 TensorRT Acceleration
5.4.1 TensorRT Introduction
TensorRT is a high-performance deep learning inference, includes a deep learning inference optimizer and runtime that delivers low latency and high throughput for inference applications. It is deployed to hyperscale data centers, embedded platforms, or automotive product platforms to accelerate the inference.
TensoRT supports almost all deep learning frameworks, such as TensorFlow, Caffe, Mxnet and Pytorch. Combing with new NVIDIA GPU, TensorRT can realize swift and effective deployment and inference on almost all frameworks.
To accelerate deployment inference, multiple methods to optimize the models are proposed, such as model compression, pruning, quantization and knowledge distillation. And we can use the above methods to optimize the models during training, however TensorRT optimize the trained models. It improves the model efficiency through optimizing the network computation graph.
After the network is trained, you can directly put the model training file into tensorRT without relying on deep learning framework.
5.4.2 Optimization Methods
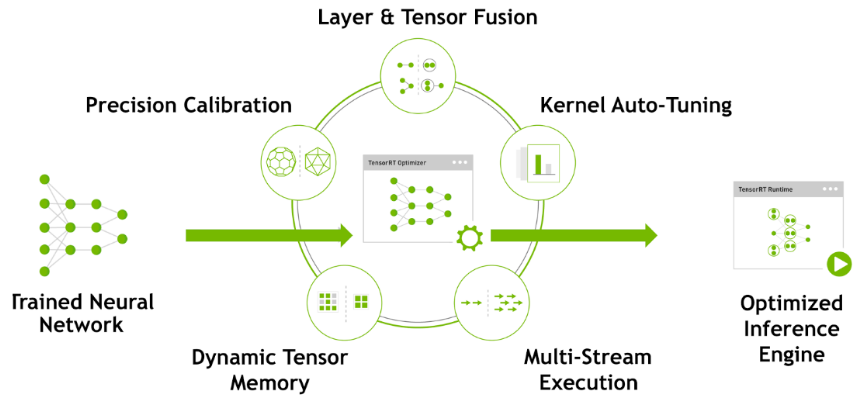
TensorRT has the following optimization strategies:
(1) Precision Calibration
(2) Layer & Tensor Fusion
(3) Kernel Auto-Tuning
(4) Dynamic Tenser Memory
(5) Multi-Stream Execution
Precision Calibration
In the training phase of neural networks across most deep learning frameworks, network tensors commonly employ 32-bit floating-point precision (FP32). Following training, since backward propagation is unnecessary during deployment inference, there is an opportunity to judiciously decrease data precision, for instance, by transitioning to FP16 or INT8. This reduction in data precision has the potential to diminish memory usage and latency, leading to a more compact model size.
The table below provides an overview of the dynamic range for different precision:
| Precision | Dynamic Range |
|---|---|
| FP32 | −3.4×1038 ~ +3.4×1038 |
| FP16 | −65504 ~- +65504 |
| INT8 | −128 ~ +127 |
INT8 is limited to 256 distinct numerical values. When INT8 is employed to represent values with FP32 precision, information loss is certain, resulting in a decline in performance. Nevertheless, TensorRT provides a fully automated calibration process to optimally align performance by converting FP32 precision data to INT8 precision, thereby minimizing performance loss.
Layer & Tensor Fusion
While CUDA cores efficiently compute tensor operations, a significant amount of time is still spent on the initialization of CUDA cores and read/write operations for each layer’s input/output tensors. This results in GPU resource wastage and creates a bottleneck in memory bandwidth.
TensorRT optimizes the model structure by horizontally or vertically merging layers, reducing the number of layers and consequently decreasing the required CUDA core count, achieving structural optimization.
Horizontal merging combines convolution, bias, and activation layers into a unified CBR structure, utilizing only one CUDA core. Vertical merging consolidates layers with identical structures but different weights into a broader layer, also using only one CUDA core.
Moreover, in cases of multi-branch merging, TensorRT can eliminate concat layers by directing layer outputs to the correct memory address without copying, thereby reducing memory access frequency.
Kernel Auto-Tuning
During the inference calculation process, the neural network model utilizes the GPU’s CUDA cores for computation. TensorRT can adjust the CUDA cores based on different algorithms, network models, and GPU platforms, ensuring that the current model can perform computational operations with optimal performance on specific platforms.
Dynamic Tenser Memory
During the utilization of each Tensor, TensorRT allocates dedicated GPU memory to prevent redundant memory requests, thereby reducing memory consumption and enhancing the efficiency of memory reuse.
Multi-Stream Execution
By leveraging CUDA Streams, parallel computation is achieved for multiple branches of the same input, maximizing the potential for parallel operations.
5.5 Yolov5 Model
5.5.1 Yolo Model Series Introduction
YOLO Series
YOLO (You Only Look Once) is an one-stage regression algorithm based on deep learning.
R-CNN series algorithm dominates target detection domain before YOLOv1 is released. It has higher detection accuracy, but cannot achieve real-time detection due to its limited detection speed engendered by its two-stage network structure.
To tackle this problem, YOLO is released. Its core idea is to redefine target detection as a regression problem, use the entire image as network input, and directly return position and category of Bounding Box at output layer. Compared with traditional methods for target detection, it distinguishes itself in high detection speed and high average accuracy.
YOLOv5
YOLOv5 is an optimized version based on previous YOLO models, whose detection speed and accuracy is greatly improved.
In general, a target detection algorithm is divided into 4 modules, namely input end, reference network, Neck network and Head output end. The following analysis of improvements in YOLOv5 rests on these four modules.
(1) Input end: YOLOv5 employs Mosaic data enhancement method to increase model training speed and network accuracy at the stage of model training. Meanwhile, adaptive anchor box calculation and adaptive image scaling methods are proposed.
(2) Reference network: Focus structure and CPS structure are introduced in YOLOv5.
(3) Neck network: same as YOLOv4, Neck network of YOLOv5 adopts FPN+PAN structure, but they differ in implementation details.
(4) Head output layer: YOLOv5 inherits anchor box mechanism of output layer from YOLOv4. The main improvement is that loss function GIOU_Loss, and DIOU_nms for prediction box screening are adopted.
5.5.2 YOLOv5 Model Structure
Component
(1) Convolution layer: extract features of the image
Convolution refers to the effect of a phenomenon, action or process that occurs repeatedly over time, impacting the current state of things. Convolution can be divided into two components: “volume” and “accumulation”. “Volume” involves data flipping, while “accumulation” refers to the accumulation of the influence of past data on current data. Flipping the data helps to establish the relationships between data points, providing a reference for calculating the influence of past data on the current data.
In YOLOv5, the data being processed is typically an image, which is two-dimensional in computer vision. Therefore, the convolution applied is also a two-dimensional convolution, with the aim of extracting features from the image. The convolution kernel is an unit area used for each calculation, typically in pixels. The kernel slides over the image, with the size of the kernel being manually set.
During convolution, the periphery of the image may remain unchanged or be expanded as needed, and the convolution result is then placed back into the corresponding position in the image. For instance, if an image has a resolution of 6×6, it may be first expanded to a 7×7 image, and then substituted into the convolution kernel for calculation. The resulting data is then refilled into a blank image with a resolution of 6×6.
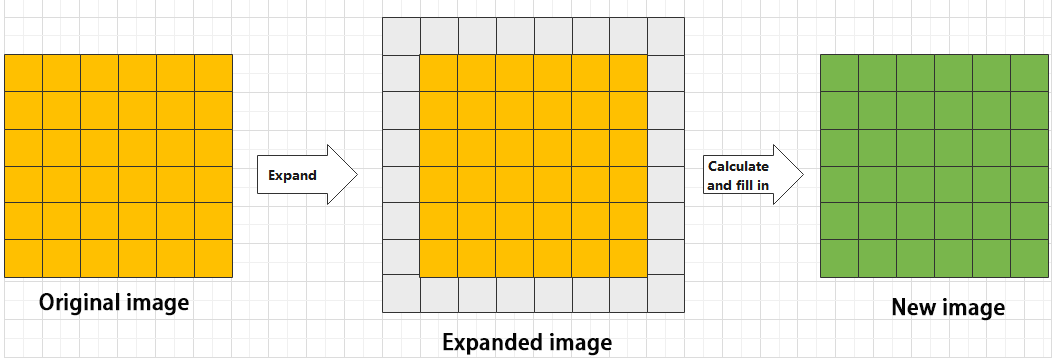
(2) Pooling layer: enlarge the features of image
The pooling layer is an essential part of a convolutional neural network and is commonly used for downsampling image features. It is typically used in combination with the convolutional layer. The purpose of the pooling layer is to reduce the spatial dimension of the feature map and extract the most important features.
There are different types of pooling techniques available, including global pooling, average pooling, maximum pooling, and more. Each technique has its unique effect on the features extracted from the image.
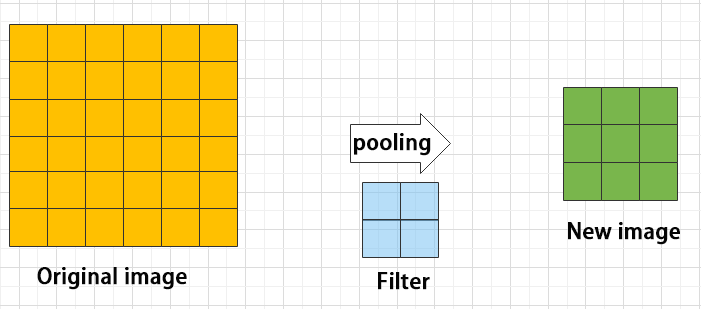
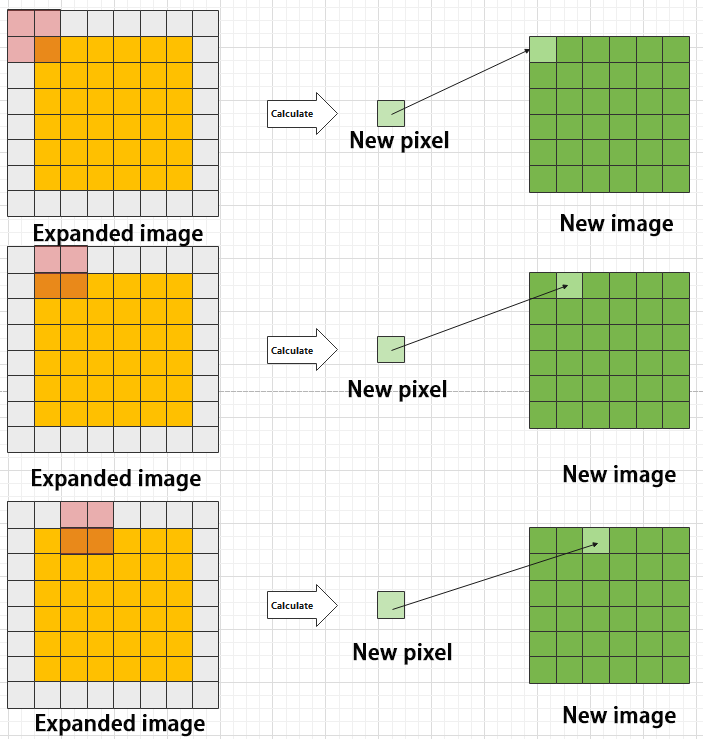
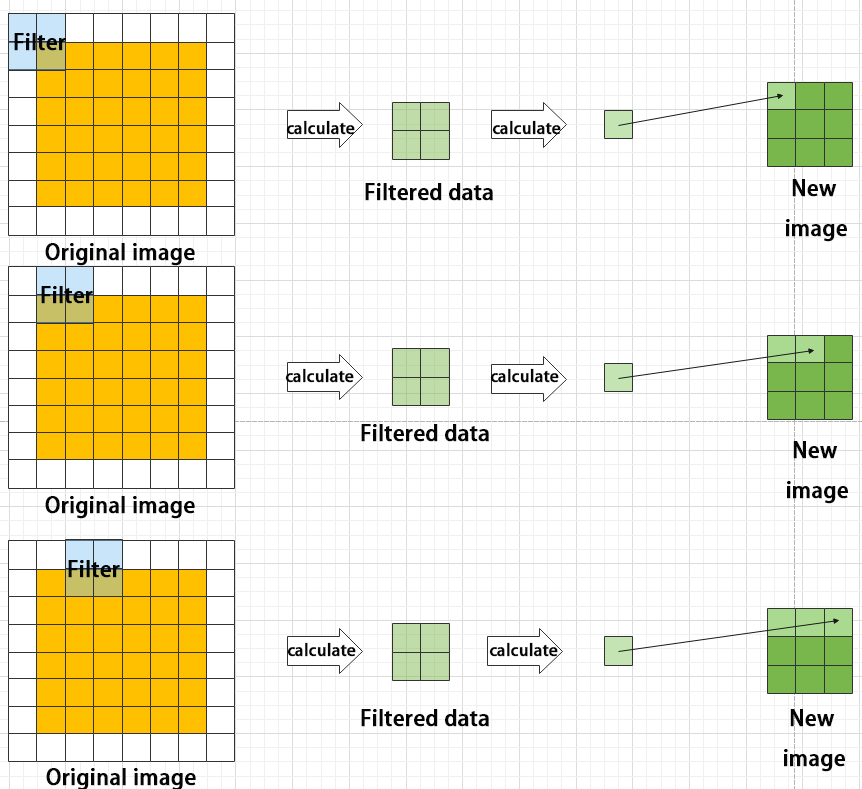
Maximum pooling can extract the most distinctive features from an image, while discarding the remaining ones. For example, if we take an image with a resolution of 6×6 pixels, we can use a 2×2 filter to downsample the image and obtain a new image with reduced dimensions.
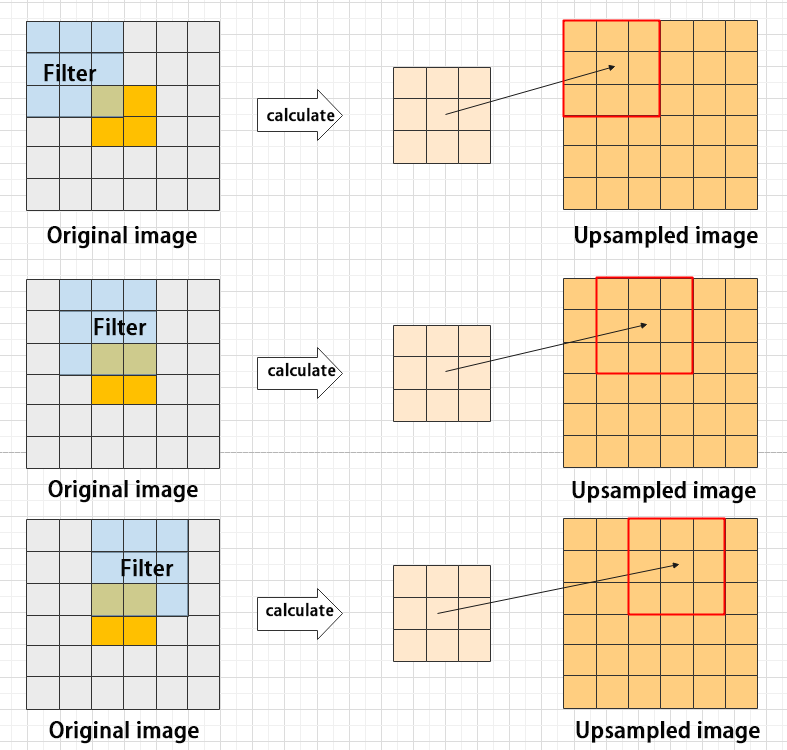
(3) Upsampling layer: restore the size of an image
This process is sometimes referred to as “anti-pooling”. While upsampling restores the size of the image, it does not fully recover the features that were lost during pooling. Instead, it tries to interpolate the missing information based on the available information.
For example, let’s consider an image with a resolution of 6×6 pixels. Before upsampling, use 3X3 filter to calculate the original image so as to get the new image.
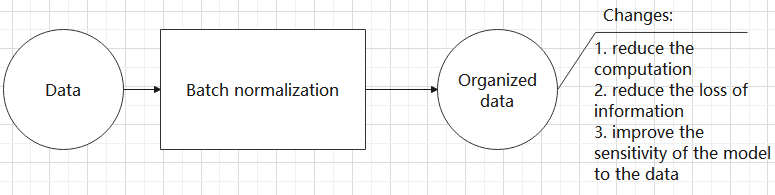
(4) Batch normalization layer: organize data
It aims to reduce the computational complexity of the model and to ensure that the data is better mapped to the activation function.
Batch normalization works by standardizing the data within each mini-batch, which reduces the loss of information during the calculation process. By retaining more features in each calculation, batch normalization can improve the sensitivity of the model to the data.
(5) RELU layer: activate function
The activation function is a crucial component in the process of building a neural network, as it helps to increase the nonlinearity of the model. Without an activation function, each layer of the network would be equivalent to a matrix multiplication, and the output of each layer would be a linear function of the input from the layer above. This would result in a neural network that is unable to learn complex relationships between the input and output.
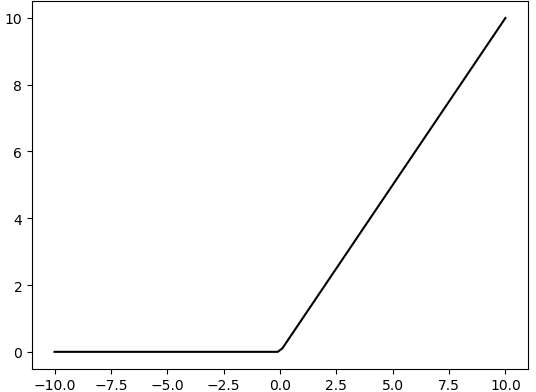
There are many different types of activation functions. Some of the most common activation functions include the ReLU, Tanh, and Sigmoid. For example, ReLU is a piecewise function that replaces all values less than zero with zero, while leaving positive values unchanged.
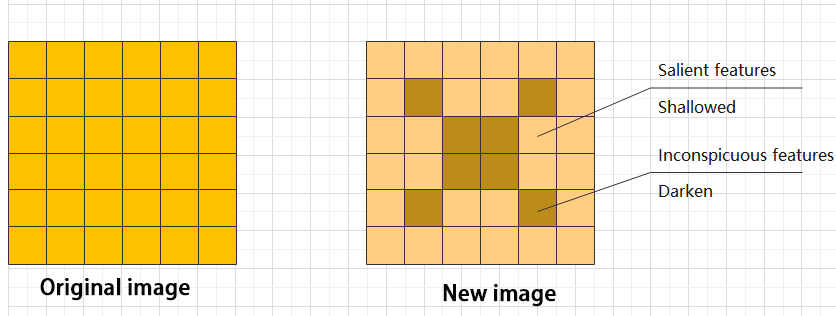
(6) ADD layer: add tensor
In a typical neural network, the features can be divided into two categories: salient features and inconspicuous features.
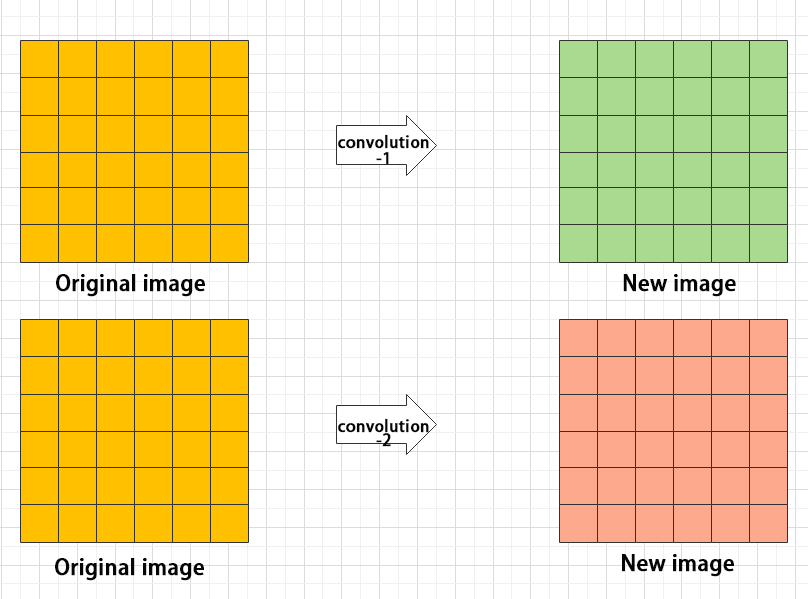
(7) Concat layer: splice tensor
It is used to splice together tensors of features, allowing for the combination of features that have been extracted in different ways. This can help to increase the richness and complexity of the feature set.
Compound Element
When building a model, using only the layers mentioned above to construct functions can lead to lengthy, disorganized, and poorly structured code. By assembling basic elements into various units and calling them accordingly, the efficiency of writing the model can be effectively improved.
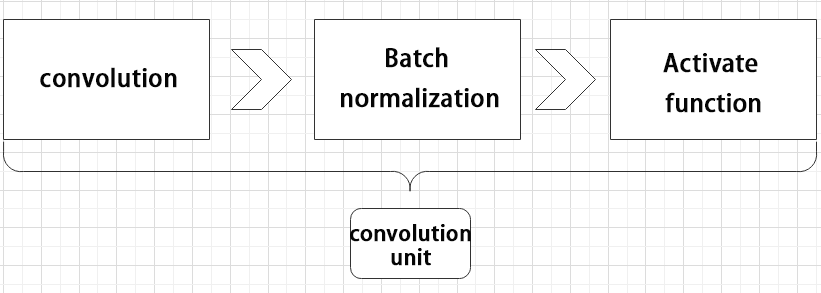
(1) Convolutional unit:
A convolutional unit consists of a convolutional layer, a batch normalization layer, and an activation function. The convolution is performed first, followed by batch normalization, and finally activated using an activation function.
(2) Focus module
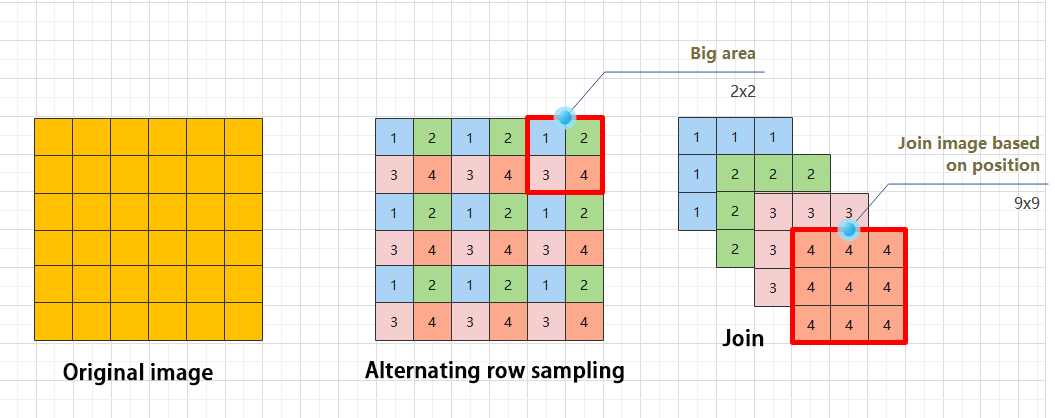
The Focus module for interleaved sampling and concatenation first divides the input image into multiple large regions and then concatenates the small images at the same position within each region to break down the input image into several smaller images. Finally, the images are preliminarily sampled using convolutional units.
As shown in the figure below, taking an image with a resolution of 6×6 as an example, if we set a large region as 2×2, then the image can be divided into 9 large regions, each containing 4 small images.
By concatenating the small images at position 1 in each large region, a 3×3 image can be obtained. The small images at other positions are similarly concatenated, and the original 6×6 image will be broken down into four 3×3 images.
(3) Residual unit
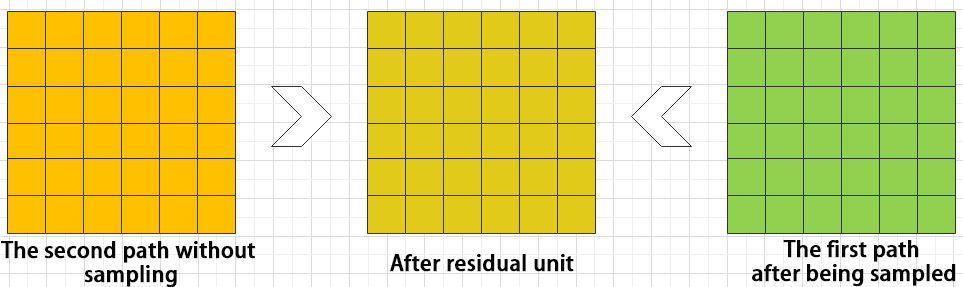
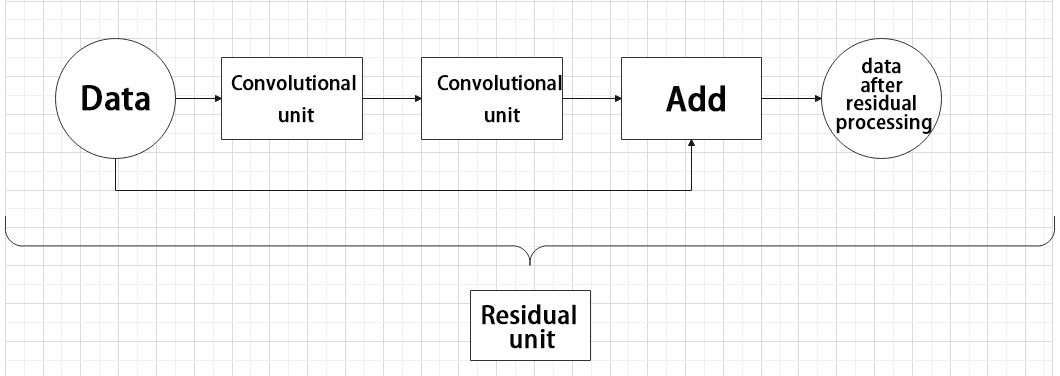
The function of the residual unit is to enable the model to learn small changes in the image. Its structure is relatively simple and is achieved by combining data from two paths.
The first path uses two convolutional units to sample the image, while the second path does not use convolutional units for sampling but directly uses the original image. Finally, the data from the first path is added to the second path.
(4) Composite Convolution Unit
In YOLOv5, the composite convolution unit is characterized by the ability to customize the convolution unit according to requirements. The composite convolution unit is also realized by superimposing data obtained from two paths.
The first path only has one convolutional layer for sampling, while the second path has 2x+1 convolutional units and one convolutional layer for sampling. After sampling and splicing, the data is organized through batch normalization and then activated by an activation function. Finally, a convolutional layer is used for sampling.’

(5) Compound Residual Convolutional Unit
The compound residual convolutional unit replaces the 2x convolutional layers in the compound convolutional unit with x residual units. In YOLOv5, the feature of the compound residual unit is mainly that the residual units can be customized according to the needs.

(6) Composite Pooling Unit
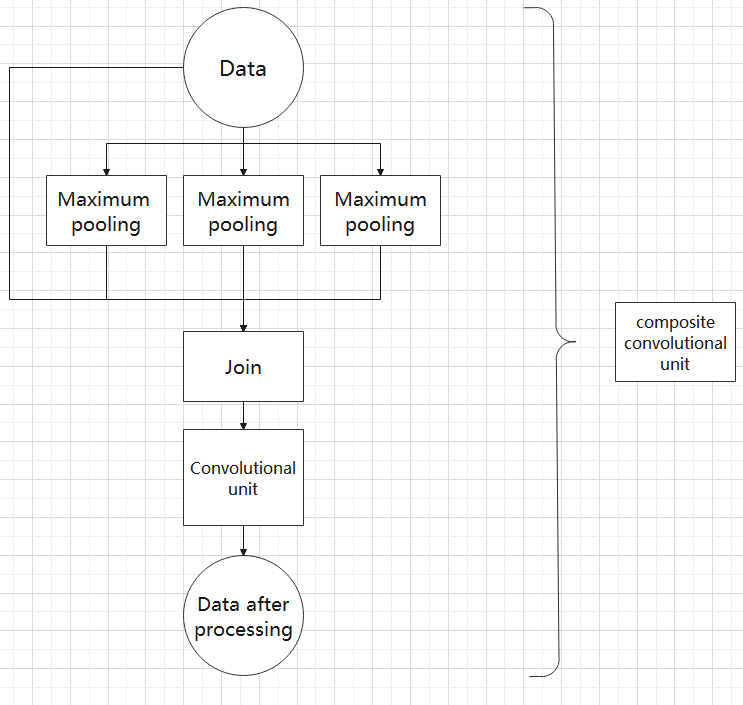
The output data of the convolutional unit is fed into three max pooling layers and an additional copy is kept without processing. Then, the data from the four paths are concatenated and input into a convolutional unit. Using the composite pooling unit to process the data can significantly enhance the features of the original data.’
Structure
Composed of three parts, YOLOv5 can output three sizes of data. Data of each size is processed in different way. The below picture is the output structure of YOLOv5.
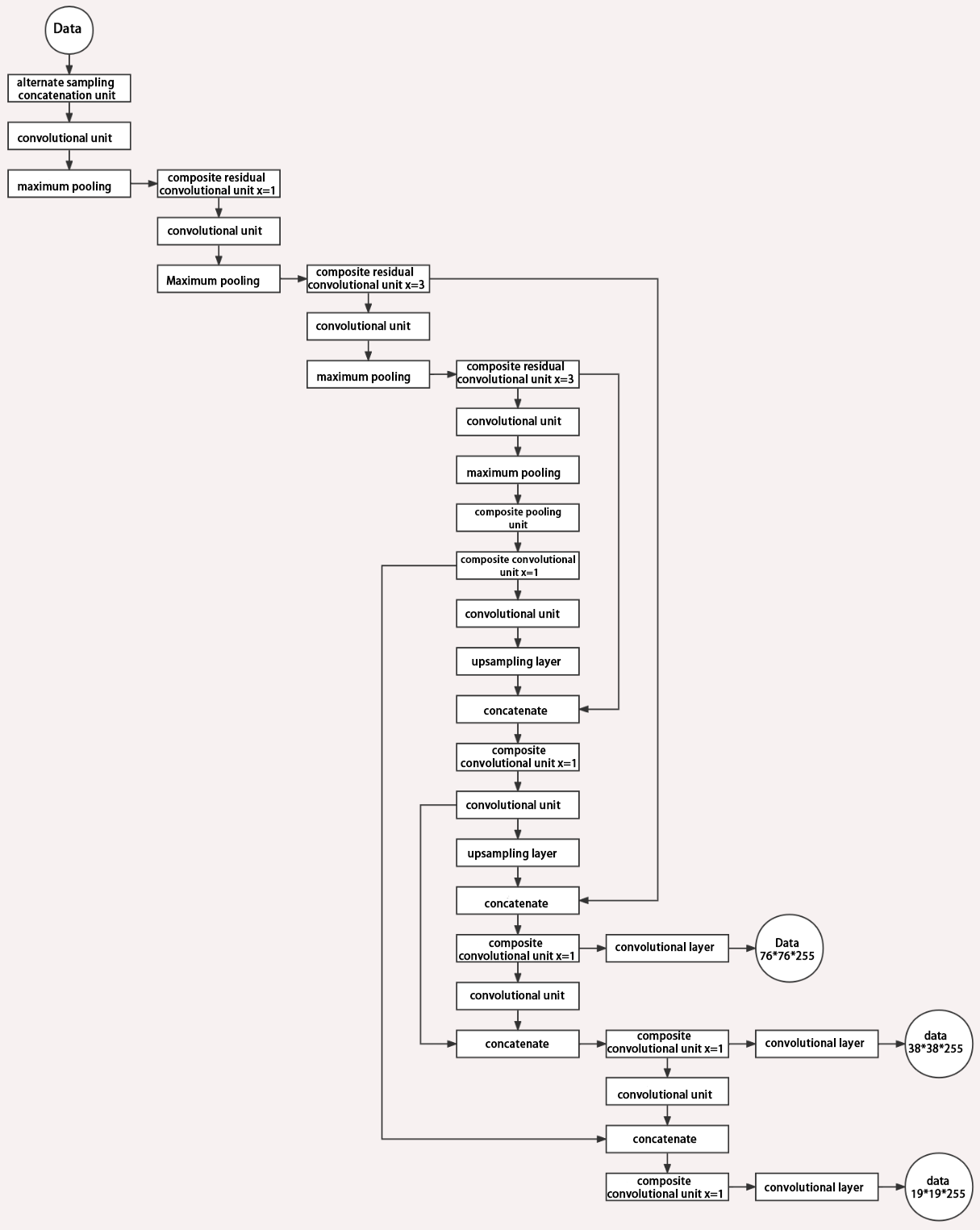
Below is the output structures of data of three sizes.
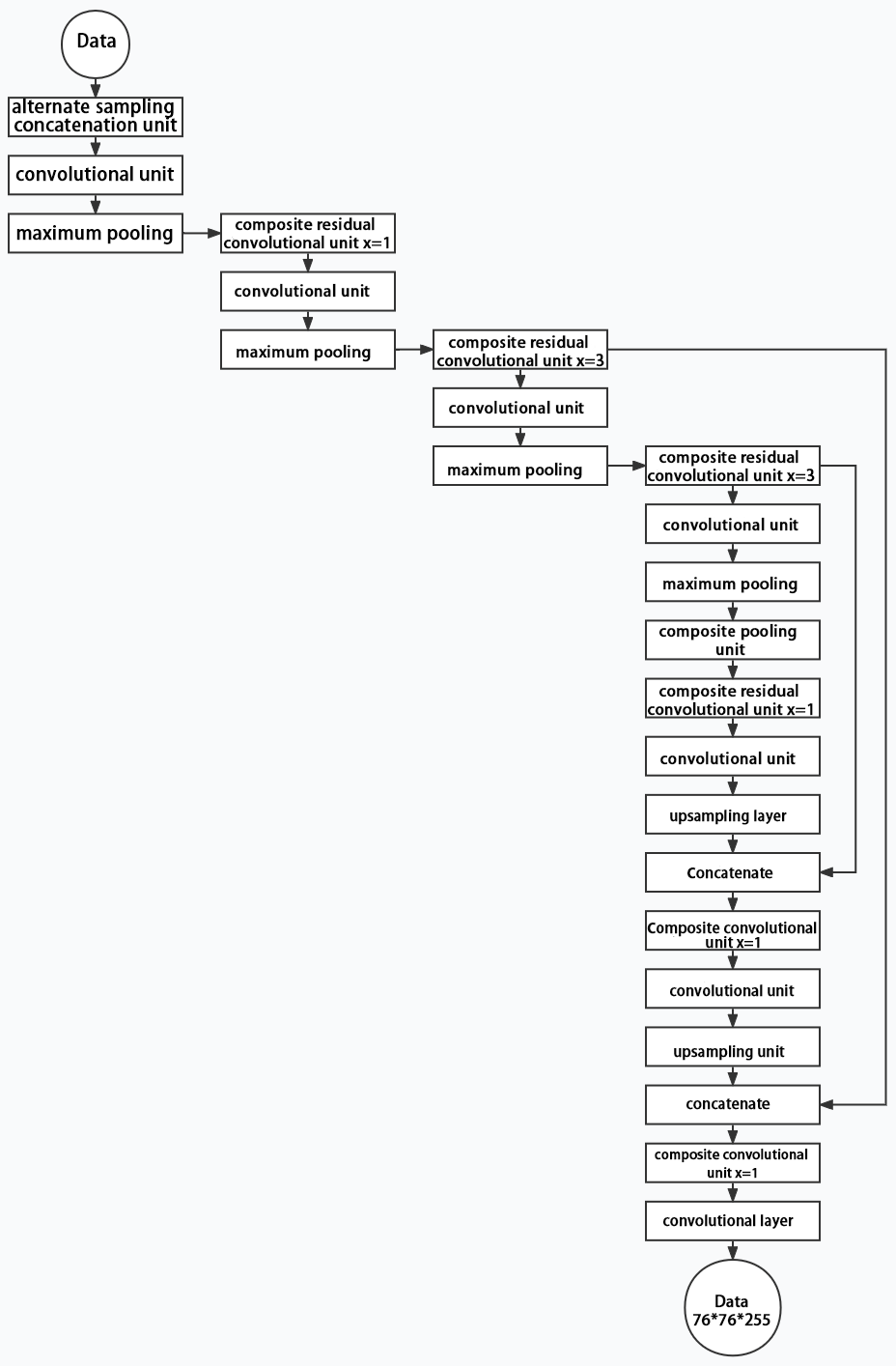
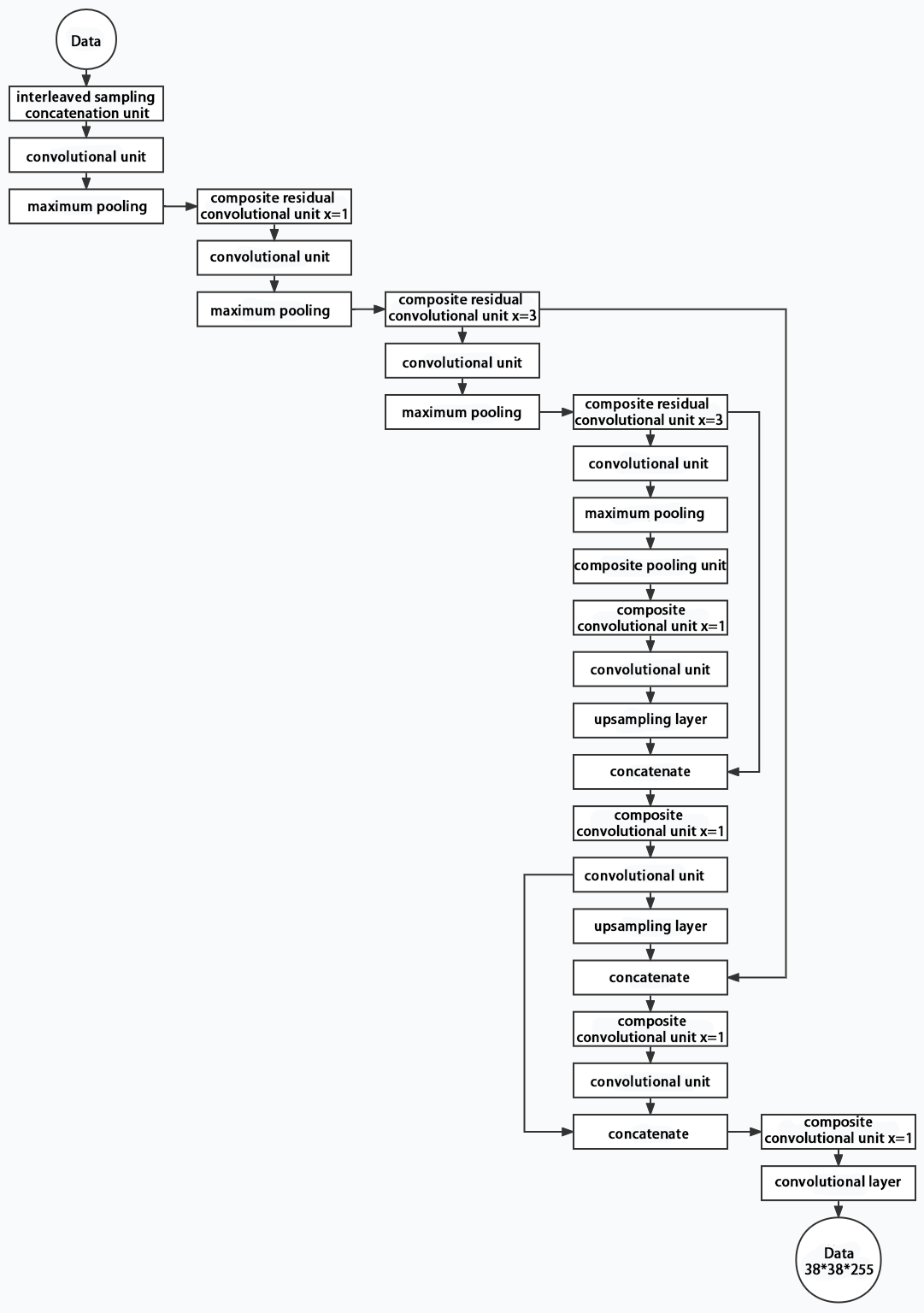
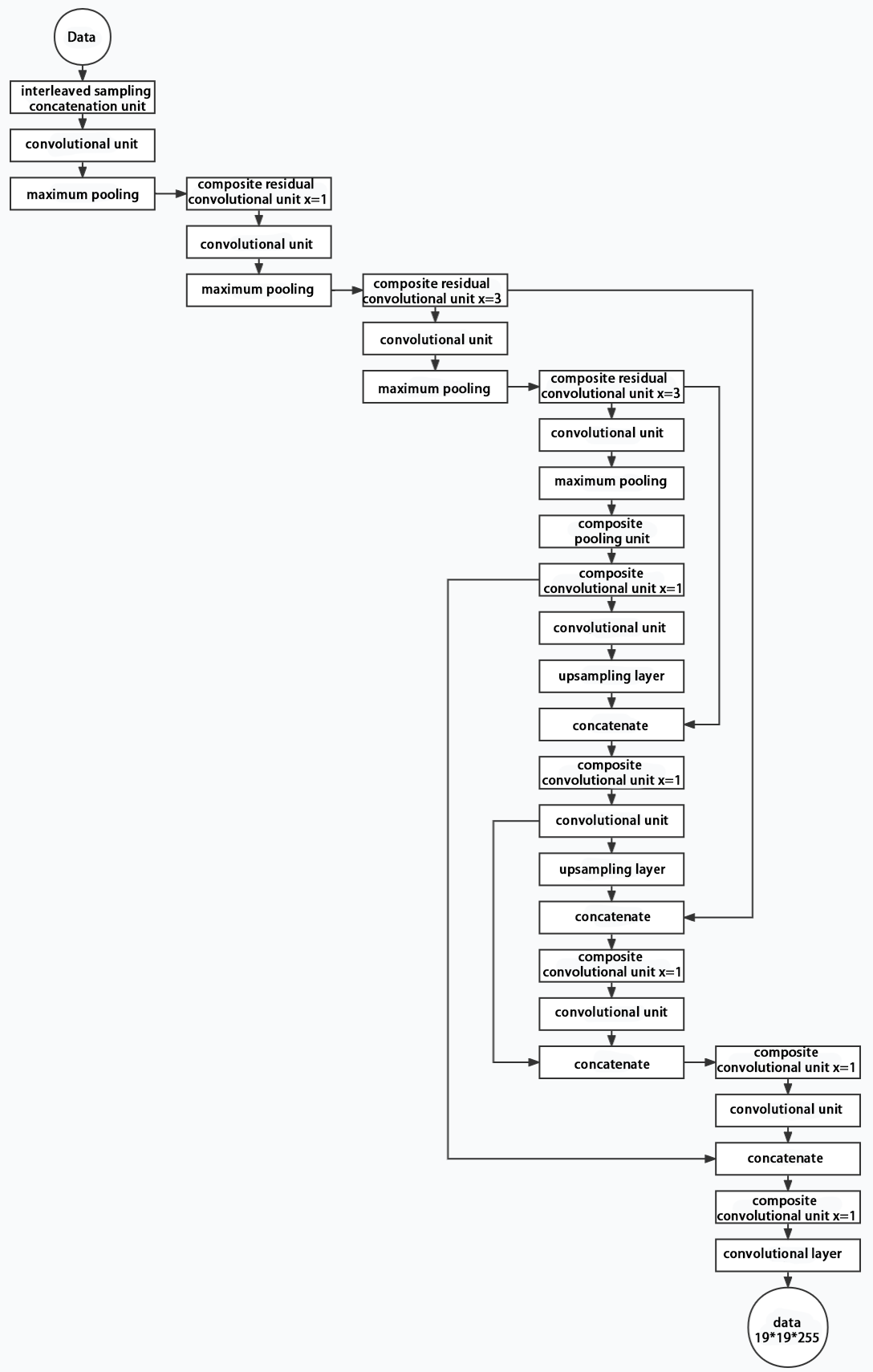
5.6 YOLOv5 Running Procedure
In this section, we provide an explanation of the model workflow using the anchor boxes, prediction boxes, and prior boxes employed in YOLOv5.
5.6.1 Prior Bounding Box
When an image is input into model, object detection area requires us to offer, while prior bounding box is that box used to mark the object detection area on image before detection.

5.6.2 Prediction Box
The prediction box is not required to set manually, which is the output result of the model. When the first batch of training data is input into model, the prediction box will be automatically generated with it. The position in which the object of same type appear more frequently are set as the center of the prediction box.

5.6.3 Anchor Box
After the prediction box is generated, deviation may occur in its size and position. At this time, the anchor box serves to calibrate the size and position of the prediction box.
The generation position of anchor box is determined by prediction box. In order to influence the position of the next generation of the prediction box, the anchor box is generated at the relative center of the existing prediction box.

5.6.4 Realization Process
After the data is calibrated, a prior bounding box appears on image. Then, the image data is input to the model, the model generates a prediction box based on the position of the prior bounding box. Having generated the prediction box, an anchor box will appear automatically. Lastly, the weights from this training are updated into model.
Each newly generated prediction will be influenced by the last generated anchor box. Repeating the operations above continuously, the deviation of the size and position of the prediction box will be gradually erased until it coincides with the priori box.

5.7 Object Detection Model Training
Note
A wired connection using an Ethernet cable is required during the model training process. Users should prepare an Ethernet cable in advance for connecting the robot.
5.7.1 Image Collecting
To effectively train the Yolov5 model, a substantial amount of data is necessary. Thus, it is crucial to collect and annotate data as part of the preparation for the subsequent model training.
Please begin by preparing the images that need to be collected. To illustrate this process, we can use waste cards as an example.
Preparation
The training of image datasets requires a considerable amount of swap space. Since the initial system space may be insufficient, it needs to be reallocated.
(1) Enter the command ‘df -h’ to check the system’s memory space and ensure that the size of the system files is approximately the same as the size of the SD card.
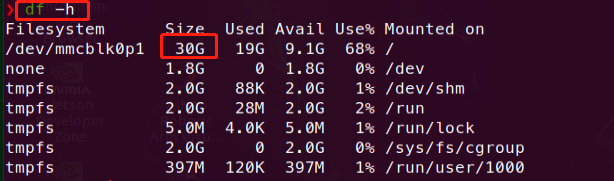
If the sizes are not consistent, enter the command ‘sudo expand_fs.sh.’ The system will check if expansion is currently in progress; if not, it will extend the system memory to occupy the entire SD card.
sudo expand_fs.sh
Create New Dataset Folder
Create a new folder (e.g., ‘My_Data’—please choose a specific name of your choice; we have already set this up in the system) to store your dataset. To prevent the training process from interfering with the normal use of other files, it is recommended to create the folder under the ‘Home’ path in Files. After entering the command, you should see the newly created folder.
mkdir My_data
ls

(1) Within the newly created ‘My_Data’ folder, create three additional directories: ‘Annotations’ (for storing annotation files), ‘ImageSets’ (for storing dataset path files), and ‘JPEGImages’ (for storing dataset images). After entering the command, you should see three new folders.
mkdir -p My_data/Annotations My_data/ImageSets My_data/JPEGImages
cd My_data
ls

Image Collecting
(1) Start the robot, and access the robot system desktop using NoMachine.
(2) Click-on  to open the command-line terminal. Execute the command below to terminate the app auto-start service.
to open the command-line terminal. Execute the command below to terminate the app auto-start service.
~/.stop_ros.sh
(3) Run the command below to initiate the camera service.
roslaunch jetarm_peripherals camera.launch
(4) Double-click to open the image collecting tool.
rosrun dataset_capture main.py
Note
The model reliability is contingent on having a sufficient quantity of image materials. For instance, when annotating garbage cards, it is recommended to have over 200 images per garbage card for a relatively better performance. The more images available, the better the recognition performance, with the relationship between the final number of images and recognition effectiveness following a curved trend.
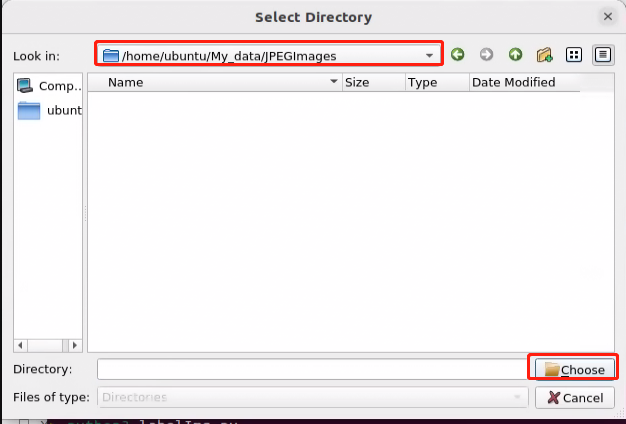
(5) In the camera interface, click on ‘Select,’ then in the pop-up window, choose ‘/home/ubuntu/My_data/JPEGImages,’ and click ‘Open’ to save the image materials to that path.
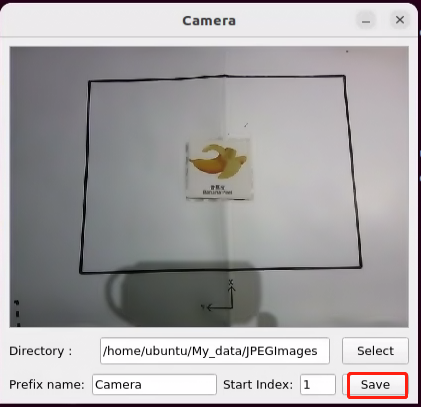
(6) Place the cards to be trained within the camera’s field of view, and click ‘Save’ each time you capture an image to save the current frame.
Note
To enhance the reliability of the model, please capture target recognition content from different distances, rotation angles, and tilt angles.
For stable recognition, it is advisable to use a significant number of images for training. Specifically, aim for at least 150 images per category when collecting training data.
Note
When saving images, ensure to capture the same image from multiple angles in the following scenarios:
Varied distances.
Different angles.
Various tilt degrees.
Diverse lighting conditions.
Different backgrounds (black and white are sufficient).
(7) At this point, the ‘JPEGImages’ folder within the ‘My_Data’ directory will automatically generate the captured images for the dataset.

(8) After collecting a sufficient number of images (approximately 70 to 100 images per category), if you wish to exit, click the exit button and press ‘Ctrl+C’ in the terminal to close the camera service.
(9) Next, proceed to Image Annotation for further instructions.
Image Annotation
Labeling images is indispensable to functional datasets because It enables training model know what classes are important parts of the image so as to identify those classes in new images.
Note
the input command should be case sensitive, and the keywords can be complemented using Tab key.
(1) Enter the following command to launch the image labeling tool.
python3 factory_utils/labelImg/labelImg.py
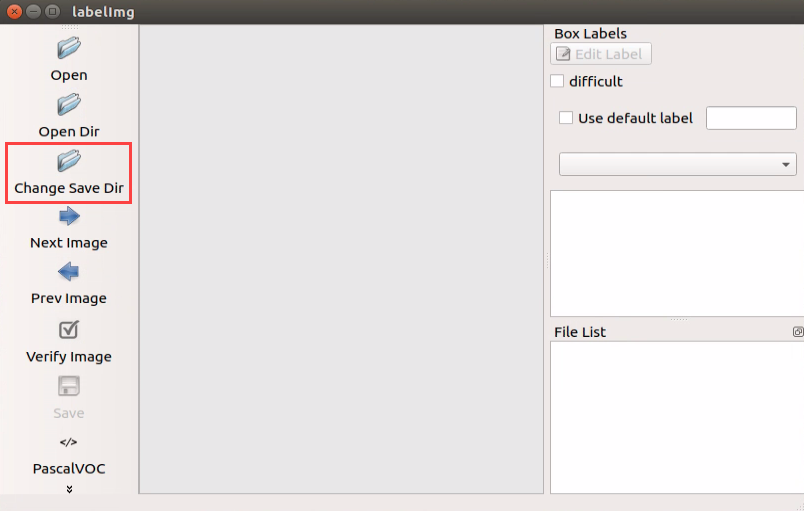
(2) Upon opening, click ‘Change Save Dir’ first to set the save path for annotation data. Choose ‘/home/ubuntu/My_Data/Annotations’ here, and then click ‘Open’ to proceed.
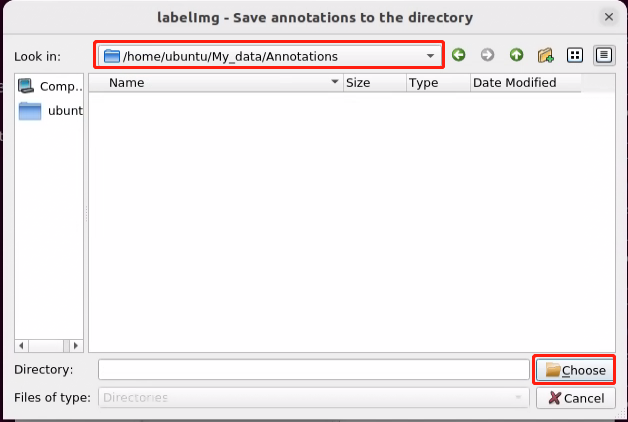
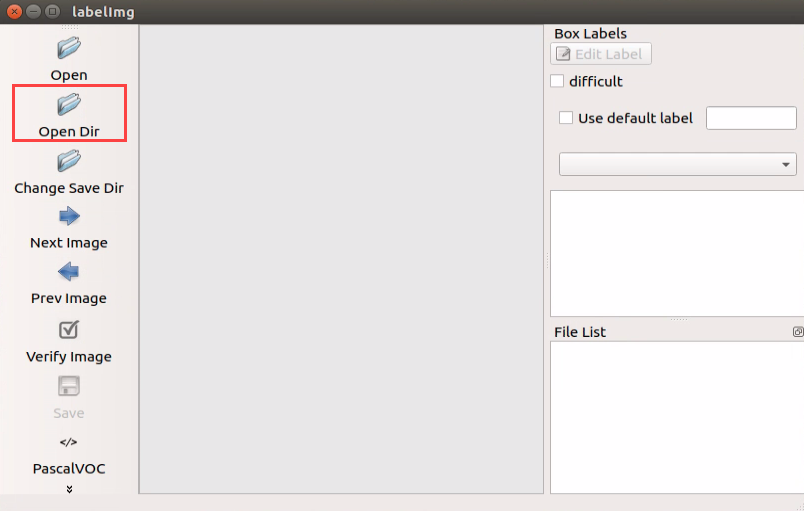
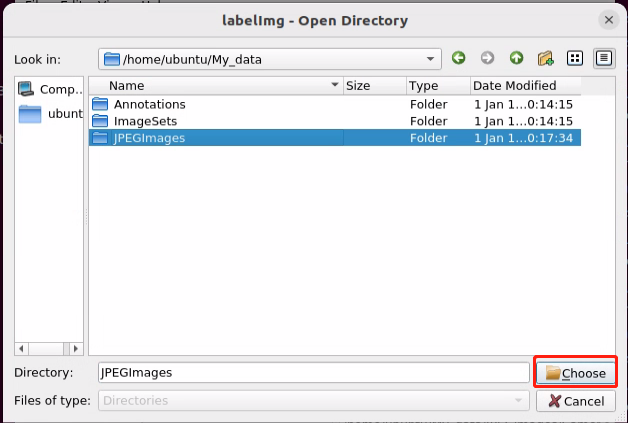
(3) Start by clicking ‘Open Dir’ to access the folder where we store the images. Choose ‘/home/ubuntu/My_Data/JPEGImage’ here, and then click ‘Open’ to proceed.
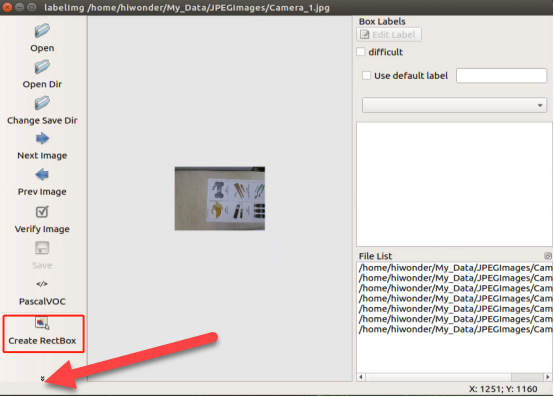
(4) Click ‘Create RectBox’ in the left toolbar to establish an annotation box. If you cannot find the corresponding tool, you can click on the location indicated by the red arrow.
(5) Move the mouse to the appropriate position, then hold down the left mouse button and drag to create a rectangular box around the training content in the photo. Here, we use a banana card as an example.
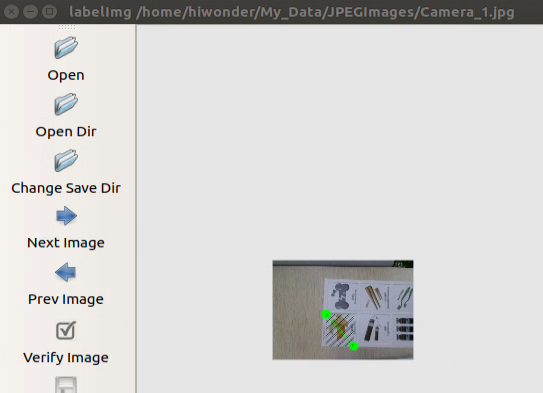
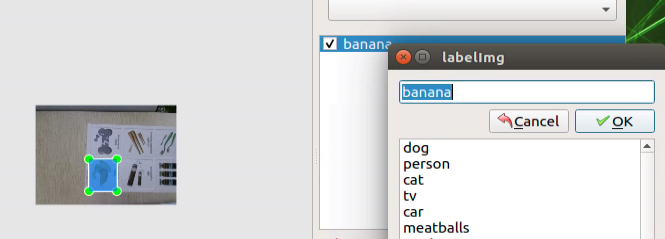
(6) After releasing the mouse, input the category name of the card in the dialog box that appears, and then click ‘OK.’ For example, if it’s a banana card, you can enter ‘banana.’
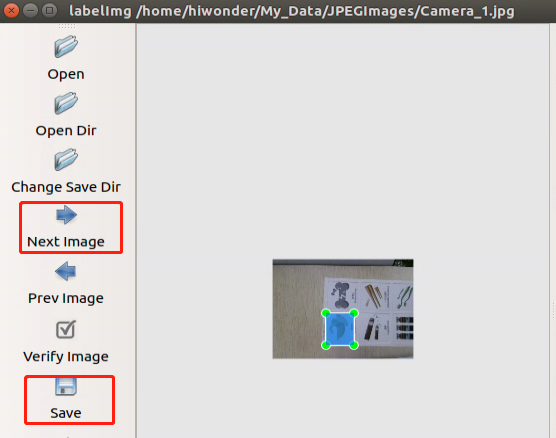
(7) After completing the annotation for one image, click ‘Save’ to save, and then continue by clicking ‘Next Image’ to annotate the next one.
Note
Shortcuts can be used during annotation to speed up the process. For example, pressing ‘D’ can switch to the next image, and pressing ‘W’ can create an annotation box.
You can also press ‘Ctrl+V’ to paste the annotation box from the previous image, but this method is only suitable for annotating images of the same category. This is because when pasting the annotation box, it will also include the name information of the previous image.
(8) Upon completing the annotation of all materials, XML format files with the same names as the image files will be generated inside the “Annotations” folder. (Note: For the model to be reliable, a sufficient number of image materials is required—collect 70 to 100 images for each category.)

The function of each icon is as below:
| Icon | Shortcut Key | Function |
|---|---|---|
 |
Ctrl+U | Select the directory where the picture is saved. |
 |
Ctrl+R | Select the directory where the calibration data is saved. |
 |
W | Create annotation box |
 |
Ctrl+S | Save annotation |
 |
A | Switch to the previous image |
 |
D | Switch to the next image |
(9) After completing the annotation, press ‘Ctrl+C’ to close the depth camera service, and close both the camera and the annotation tool.
(10) Open a new terminal, and execute this command ‘cd /My_Data’ and press Enter.
cd /My_Data
(11) Enter the command ‘touch classes.names’ and press Enter to create the classes.names file.
touch classes.names
(12) Execute the command ‘vim classes.names’ to access the file.
vim classes.names
(13) Click the ‘I’ key to enter edit mode and add the class names for target recognition content. When adding multiple class names, each class name should be on a separate line. (The class names must match those used when collecting the images.)

Note
The class names added here must match the naming used in the ‘labelImg’ image annotation software.
(14) After input, press Esc key, and input “:wq” to save and close the file.
:wq
(15) Drag and copy the ‘txt_gen.py’ and ‘xml2yolo.py’ files from the same directory as this document into the ‘My_Data’ folder.
(16) Enter the command to convert the data format and press Enter.
python3 xml2yolo.py --data /home/ubuntu/My_data --yaml /home/ubuntu/My_data/data.yaml
If you see a prompt similar to the image below, the conversion was successful (the image shown is for example purposes only; please refer to the actual number of images).

(17) Move to 5.7.2 Model Training to proceed with learning.
5.7.2 Model Training
(1) Execute the command ‘cd yolov5’ to navigate to the yolov5 directory.
cd yolov5
(2) Run the command and hit Enter to train the model.
python3 train.py --data /home/ubuntu/My_data/data.yaml --weights yolov5s.pt --img 160 --epochs 10 --batch 8
In the command, ‘–img’ represents the image size; ‘–batch’ is the number of images per batch; ‘–epochs’ denotes the number of training epochs; ‘–data’ indicates the path to the dataset, and ‘–weights’ specifies the type of network for training. Users can modify the above parameters based on their specific needs. If you aim to improve model reliability, you may increase the number of training epochs, but be aware that this will also increase the training time accordingly.
(3) The training result is as below.
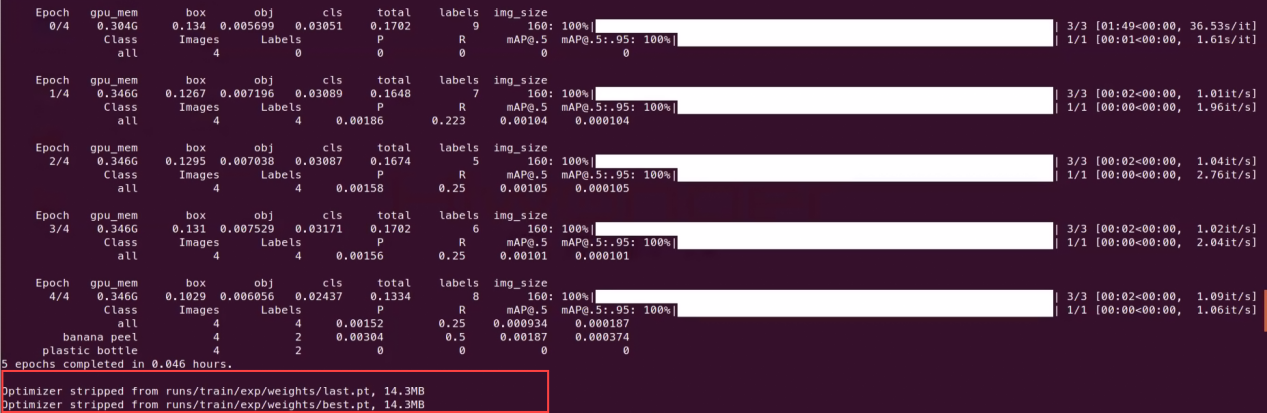
(4) The relevant files will be generated in the ‘~/yolov5/runs/train/’ folder.

Note
If multiple training sessions are conducted, the ‘exp’ folder naming here may vary. For example, it might be modified to ‘exp2,’ ‘exp3,’ etc. Subsequent steps will depend on the folder naming used in this particular step.
(5) Go to 5.7.3 Model Transformation section for learning.
5.7.3 Model Transformation
After completing the model training, the model files will be located in the path highlighted by the red box in the image below.
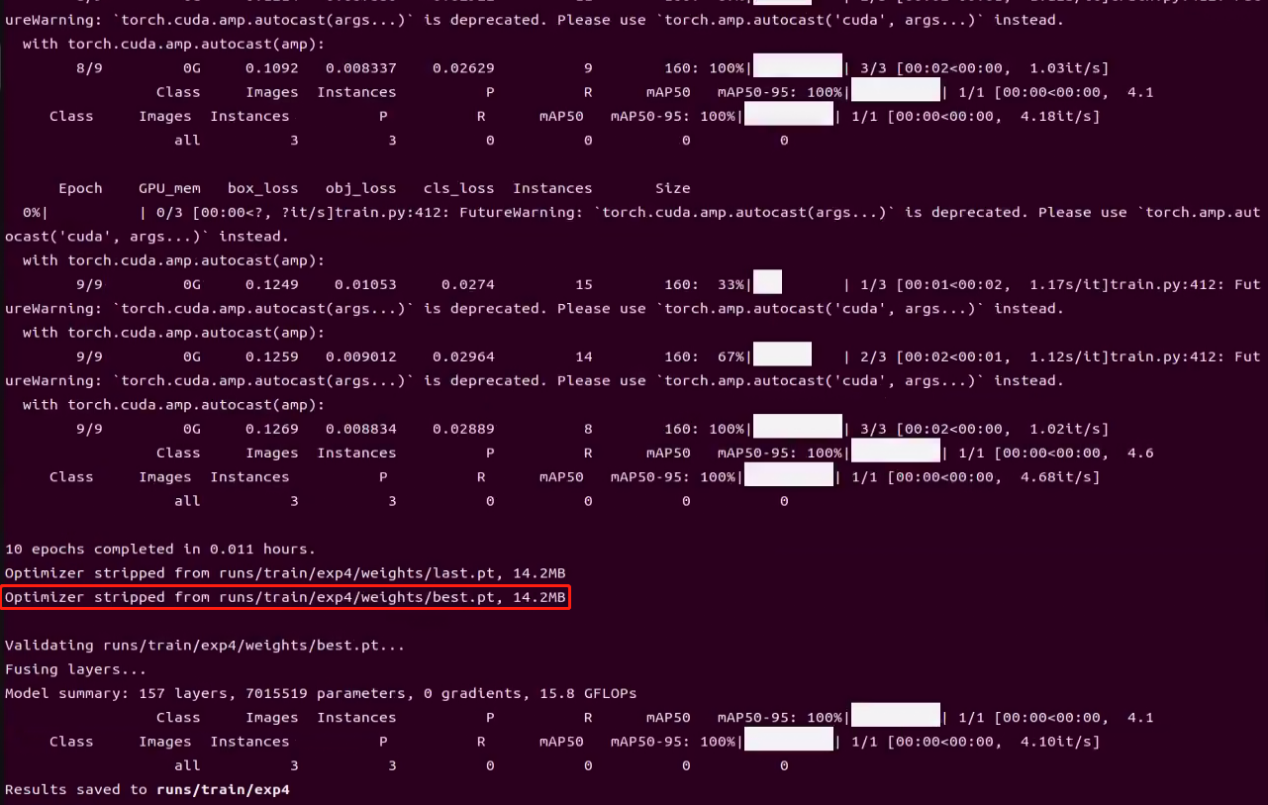
Execute the following command to convert the model.
python3 export.py --weights /home/ubuntu/yolov5/runs/train/exp4/weights/best.pt --include onnx --img 480 640
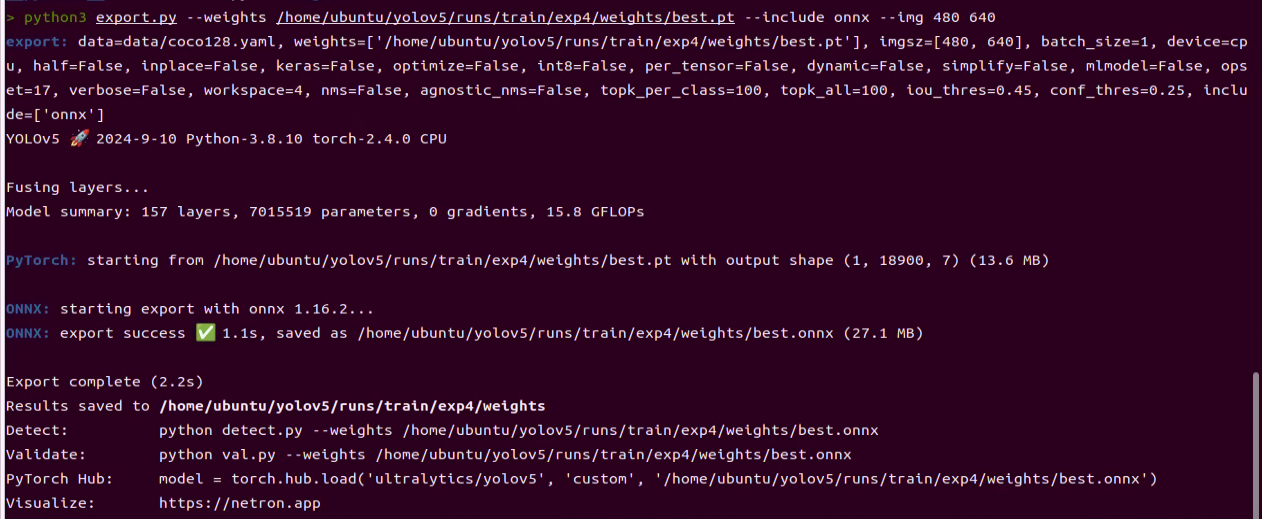
‘–weights /home/ubuntu/yolov5/runs/train/exp4/weights/best.pt’ is the path to the generated .pt model. ‘–include onnx’ converts it to the ONNX model. ‘–img 480 640’ specifies the image dimensions for model inference, with 480 representing the image height and 640 representing the image width.
5.7.4 Model Invoking
(1) Run the following command:
cd jetarm/src/jetarm_6dof/jetarm_6dof_app/scripts
(2) Enter the command below:
vim yolov5_onnx.py
Note
It is recommended to back up this file before making any modifications. If you make a mistake, you can restore the backup; however, if you modify it directly and encounter an error, it may cause other routines to malfunction.
(3) Scroll to the bottom of the document to find the section shown in the image below:
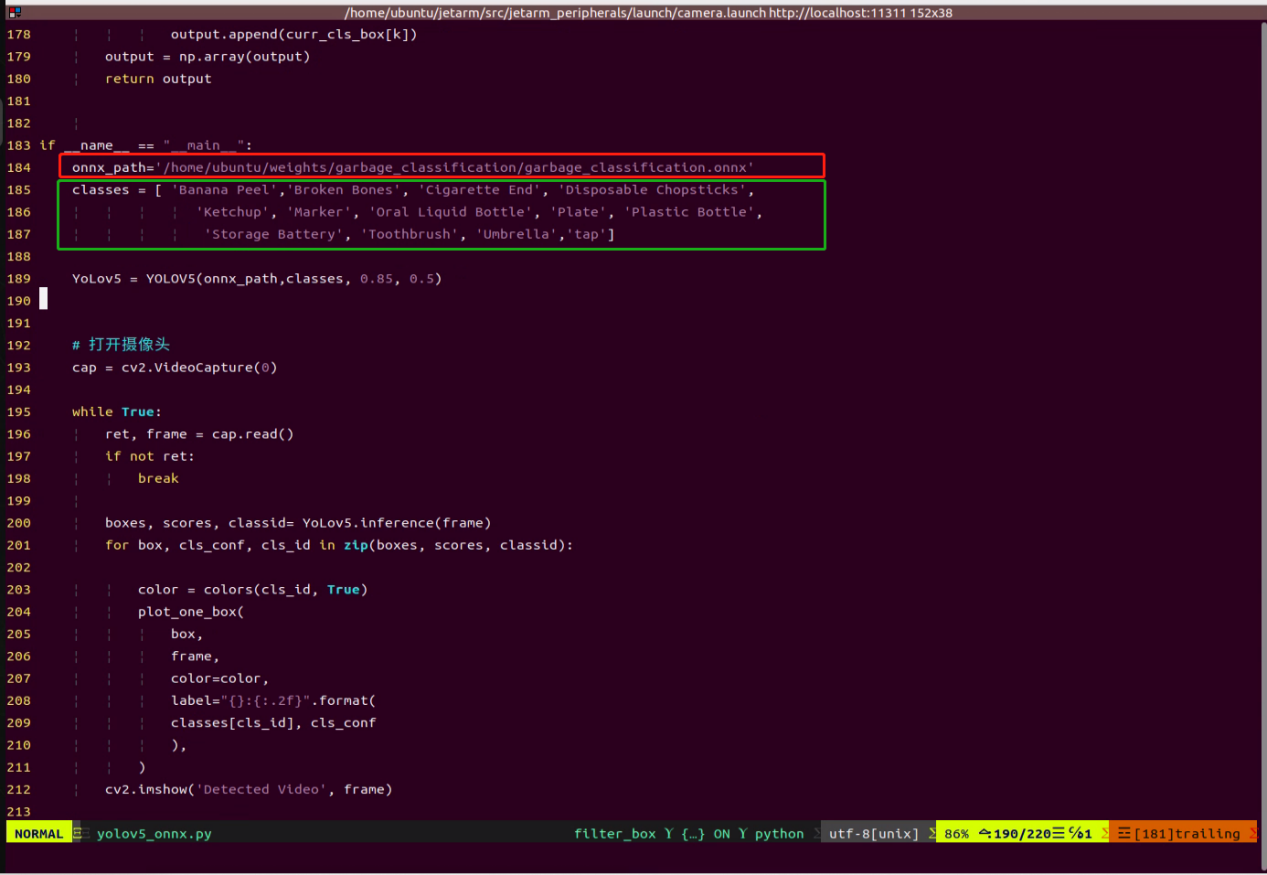
The first red box highlights the trained model that has been accelerated, located at ‘/home/ubuntu/weights/garbage_classification/’. Users need to modify this based on its naming.
The second green box indicates the image categories for the trained model. The names entered here must match the order used during model annotation and in the ‘classes.names’ file to avoid errors in model recognition.
(4) After making the modifications, press ‘Esc’ and then enter ‘:wq’ to save the changes and exit.
(5) Run the following command to initiate the target detection.
python3 yolov5_onnx.py